Descifrando las Matrices de Confusión: No Tan Confuso Como Parece
Las matrices de confusión pueden sonar como un concepto intimidante, reservado solo para matemáticos y científicos de datos, pero en realidad, son una herramienta esencial y accesible para evaluar el rendimiento de los modelos de clasificación. Vamos a adentrarnos en este concepto sin rodeos y descubrir cómo las matrices de confusión nos proporcionan información valiosa.
Desentrañando el Término
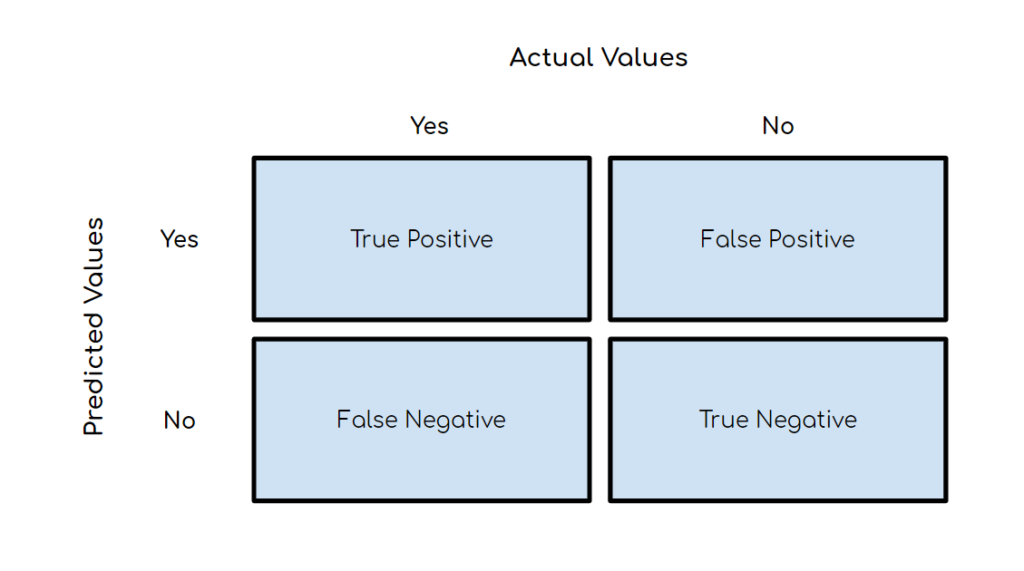
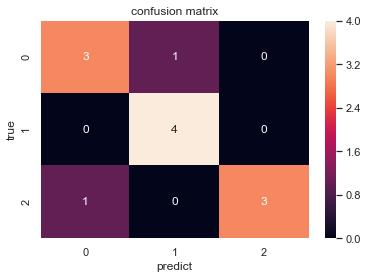
Empecemos por definir lo que es una matriz de confusión. En su esencia, es una tabla que compara las predicciones de un modelo con los resultados reales. A través de esta tabla, podemos determinar cómo el modelo se comporta en términos de aciertos y errores. Imagina una especie de informe de detectives donde comparamos lo que se esperaba con lo que realmente sucedió.
Los Elementos de la Matriz de Confusión
Una matriz de confusión generalmente se divide en cuatro categorías:
Verdaderos Positivos (VP): Estos son los casos en los que el modelo predijo correctamente una clase positiva. Por ejemplo, si estás trabajando en un modelo para diagnosticar enfermedades, los VP representarían los casos en los que el modelo acertó al decir que alguien tenía la enfermedad y, de hecho, la tenía.
Verdaderos Negativos (VN): En esta categoría, el modelo predijo correctamente una clase negativa. Siguiendo el ejemplo médico, los VN serían los casos en los que el modelo acertó al decir que alguien estaba sano y, de hecho, lo estaba.
Falsos Positivos (FP): Aquí es donde comienzan los errores. Los FP representan los casos en los que el modelo predijo incorrectamente que algo pertenecía a la clase positiva cuando, en realidad, no lo hacía. En el contexto médico, serían personas sanas que el modelo diagnosticó incorrectamente como enfermas.
Falsos Negativos (FN): Nuevamente, estamos en el terreno de los errores. Los FN son casos en los que el modelo predijo incorrectamente que algo no pertenecía a la clase positiva cuando, en realidad, sí lo hacía. Esto significaría que alguien enfermo fue considerado sano por el modelo.
La Utilidad de las Matrices de Confusión
La pregunta obvia es: «¿Para qué necesitamos todo esto?» Bueno, la matriz de confusión es una herramienta esencial para evaluar el rendimiento de un modelo. Es como un espejo que refleja el desempeño del modelo y resalta sus puntos fuertes y débiles. A través de la matriz de confusión, podemos calcular varias métricas clave que nos dicen qué tan efectivo es nuestro modelo. Algunas de estas métricas incluyen:
Precisión: Mide qué tan preciso es el modelo en general y se calcula como (VP) / (VP + FP). Una precisión más alta es mejor.
Recall (Recuperación): Indica cuántos de los casos positivos reales el modelo identificó correctamente y se calcula como (VP) / (VP + FN). Aquí también, un valor más alto es preferible.
F1-Score: Esta métrica combina precisión y recuperación para brindar una evaluación más completa del rendimiento del modelo. Un F1-Score más alto es deseable.
Un Ejemplo Práctico
Para ilustrar esto en un contexto práctico, consideremos un modelo que predice si lloverá o no. Los VP serían los días en que el modelo predijo «lluvia» y efectivamente llovió. Los VN serían los días en que predijo «no lluvia» y efectivamente no llovió. Los FP serían los días en que predijo «lluvia» y no llovió, mientras que los FN serían los días en que predijo «no lluvia» y llovió.
En Resumen
Las matrices de confusión pueden parecer complejas al principio, pero son una herramienta fundamental para evaluar los modelos de clasificación. No es necesario ser un experto en matemáticas para comprenderlas; son una guía que revela dónde el modelo está funcionando bien y dónde necesita mejorar. La próxima vez que te enfrentes a una matriz de confusión, no te sientas confundido. Estás un paso más cerca de comprender cómo funciona tu modelo y cómo optimizarlo. ¡Adelante!